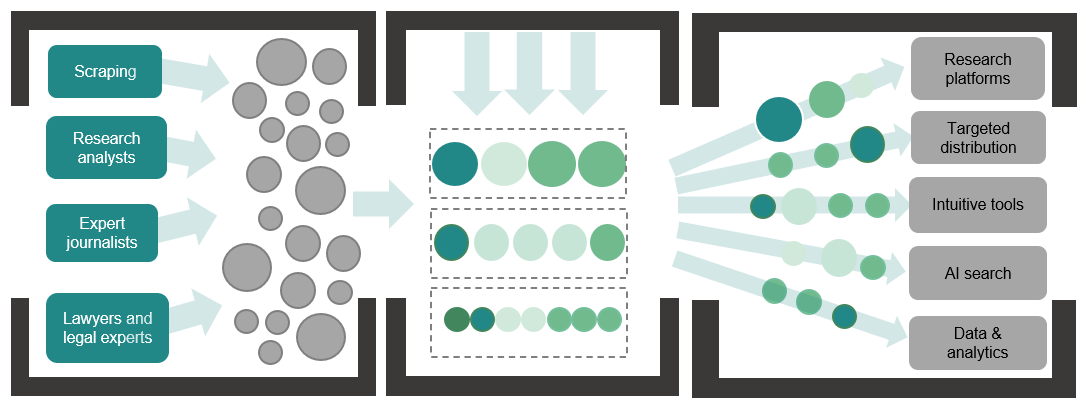
To serve clients with comprehensive legal research platforms and tools, we utilise content and data from a multitude of sources. Our technologies monitor and source legal updates and articles directly from the world’s best law firms, legislation and guidance from legislative bodies globally, case filings and decisions from courts, knowledge-sharing resources from in-house counsel, and many other resource types.
Externally sourced content sets and data points are combined with LBR’s own unique analysis and updates, provided by an expert in-house team, to form an astonishing breadth and depth of coverage of legal issues.
This raw, unstructured dataset is passed through LBR’s enrichment and processing systems, which use a combination of natural language processing, entity extraction, article and text extraction, and classification engines to result in a uniformly processed, categorised dataset that is stored in a central and accessible repository, ready to be harnessed on our platforms and served to our clients.
By applying our central taxonomy to all content sets, LBR’s products become source-agnostic, and are able to cut through the noise and distribute only the most pertinent content to our engaged and informed user base.
Meet the Team
My attitude has always been “whatever it takes”, be that PoCing a new technology or product, making architectural decisions or pitching in to investigate and fix production issues.
